一、贪心问题
贪心算法
贪心算法(greedy algorithm),是用计算机来模拟一个「贪心」的人做出决策的过程。这个人十分贪婪,每一步行动总是按某种指标选取最优的操作。而且他目光短浅,总是只看眼前,并不考虑以后可能造成的影响。
可想而知,并不是所有的时候贪心法都能获得最优解,所以一般使用贪心法的时候,都要确保自己能证明其正确性。
适用范围
贪心算法在有最优子结构的问题中尤为有效。最优子结构的意思是问题能够分解成子问题来解决,子问题的最优解能递推到最终问题的最优解。
证明
贪心算法有两种证明方法:反证法和归纳法。一般情况下,一道题只会用到其中的一种方法来证明。
1.反证法:如果交换方案中任意两个元素/相邻的两个元素后,答案不会变得更好,那么可以推定目前的解已经是最优解了。
2.归纳法:先算得出边界情况(例如 )的最优解 ,然后再证明:对于每个情况都可以由结论推导出结果。
常见题型
在OJ的问题中,最常见的贪心有两种。
1.「我们将 XXX 按照某某顺序排序,然后按某种顺序(例如从小到大)选择。」。
2.「我们每次都取 XXX 中最大/小的东西,并更新 XXX。」(有时「XXX 中最大/小的东西」可以优化,比如用优先队列维护)
二者的区别在于一种是离线的,先处理后选择;一种是在线的,边处理边选择。
排序解法
用排序法常见的情况是输入一个包含几个(一般一到两个)权值的数组,通过排序然后遍历模拟计算的方法求出最优值。
后悔解法
思路是无论当前的选项是否最优都接受,然后进行比较,如果选择之后不是最优了,则反悔,舍弃掉这个选项;否则,正式接受。如此往复。
贪心算法与动态规划的区别
贪心算法与动态规划的不同在于它对每个子问题的解决方案都做出选择,不能回退。动态规划则会保存以前的运算结果,并根据以前的结果对当前进行选择,有回退功能。
二、POJ1700 Function Run Fun
2.1问题描述
问题截图

图2.1 问题截图
输入
输入的第一行包含一个整数T(1<=T<=20),即测试用例的数量。然后是T病例。每个案例的第一行包含N,第二行包含N个整数,给出每个人过河的时间。每个案例前面都有一个空行。不会超过1000人,没有人会超过100秒才能穿越。
输出
对于每个测试用例,打印一行,其中包含所有 N 人过河所需的总秒数。
2.2解题思路
题解
在解决这道过河问题时,我们可以使用贪心算法来最小化总时间。首先,将所有人的过河速度存储在一个数组中,并对其进行排序。接着,我们考虑以下三种情况:
1.如果还有4个或更多的人未过河,我们选择最快的人和最慢的人一起过河,然后最快的人返回;接着选择次快的人和第二慢的人一起过河,再让次快的人返回。重复此过程,直到只剩下3个人或更少。我们取这两种过河方式(最快带最慢和次快,或者最快和次快带最慢和次慢)中所需时间较短的一种。
2.如果剩下3个人未过河,我们让最快的人带最慢的人过河,然后最快的人返回,再带次慢的人过河,最后最快的人再过河。这样,三个人就能全部过河。
3.如果只剩下1个或2个人未过河,那么他们一定是过河速度最快的人(或其中两个),他们可以直接过河,无需再考虑时间。
算法设计路线
这里首先读取测试用例的数量,然后依次处理每个测试用例。对于每个测试用例,读取人数nPeople和每个人的过桥时间arrTimes。将过桥时间数组进行排序,使得过桥时间从小到大排列。这样可以方便后续的贪心策略应用。从后往前处理每个人的过桥时间,采用贪心策略选择最优的过桥方案:对于当前的最大时间的两个人(arrTimes[nIndex]和arrTimes[nIndex-1]),比较两种策略:最快的两个人带最慢的一个人过桥,最快的人返回,然后再带一个最慢的人过桥,最快的人再次返回。最快的一个人带次慢的人过桥,次慢的人返回,然后再带两个人过桥,最快的人返回。比较这两种策略的时间,选择其中较小的方案并累计到总时间nTotalTime。最后,处理剩余的情况(即人数少于等于3的情况):如果剩余3个人,直接累加这3个人的过桥时间。如果剩余2个人,累加这2个人的过桥时间。如果只剩1个人,累加这个人的过桥时间。输出当前测试用例的最短过桥总时间。通过上述步骤,算法在每个测试用例中选择最优的过桥方案,确保总时间最短。
2.3 C++源代码
#include <iostream>
#include <algorithm>
using namespace std;
int main()
{
int nTestCases, nPeople, arrTimes[1001], nIndex, nTotalTime;
// 读取测试用例的数量
cin >> nTestCases;
while (nTestCases--)
{
// 读取每个测试用例中的人数
cin >> nPeople;
nTotalTime = 0;
// 读取每个人的过桥时间
for (nIndex = 0; nIndex < nPeople; nIndex++)
cin >> arrTimes[nIndex];
// 对过桥时间进行排序
sort(arrTimes, arrTimes + nPeople);
// 计算总时间
for (nIndex = nPeople - 1; nIndex > 2; nIndex -= 2)
// 比较两种过桥方案的时间并选择最优方案
if (arrTimes[0] + 2 * arrTimes[1] + arrTimes[nIndex] > 2 * arrTimes[0] + arrTimes[nIndex - 1] + arrTimes[nIndex])
nTotalTime += 2 * arrTimes[0] + arrTimes[nIndex - 1] + arrTimes[nIndex];
else
nTotalTime += arrTimes[0] + 2 * arrTimes[1] + arrTimes[nIndex];
// 处理剩余的情况
if (nIndex == 2)
nTotalTime += arrTimes[0] + arrTimes[1] + arrTimes[2];
else if (nIndex == 1)
nTotalTime += arrTimes[1];
else
nTotalTime += arrTimes[0];
// 输出结果
cout << nTotalTime << endl;
}
return 0;
}
正确结题截图
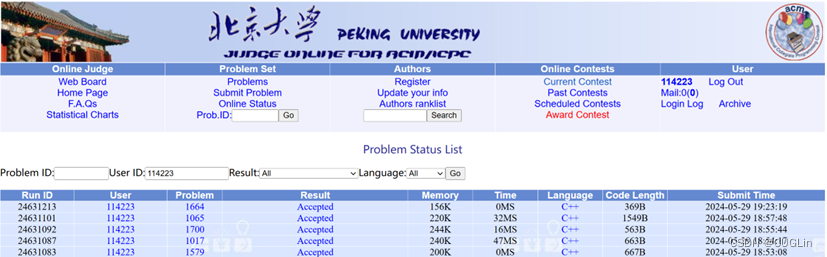
图2.2 正确解题截图
2.4复杂度分析
时间复杂度
1.读取输入:读取测试用例的数量和每个测试用例中的人数及其过桥时间需要O(n)的时间,其中n是测试用例中的人数。
2.排序:对每个测试用例中的过桥时间进行排序,使用了快速排序算法sort(arrTimes,arrTimes+nPeople),其平均时间复杂度为O(nlogn)。
3.计算总时间:在循环中处理每个过桥策略时,最多会进行n/2次迭代(因为每次迭代处理两个人)。每次迭代中的操作都是O(1)时间复杂度。因此,这部分的时间复杂度为O(n)。
4.处理剩余的情况:这部分处理的操作也是O(1)时间复杂度。
5.输出结果:输出结果需要O(1)时间复杂度。
综上所述,对于每个测试用例,主要的时间复杂度由排序过程决定,因此总的时间复杂度为O(nlogn)。假设有m个测试用例,则总的时间复杂度为O(m*nlogn)。
空间复杂度
1.空间使用:需要一个数组arrTimes来存储每个测试用例中的过桥时间,数组的大小为1001。其它变量如nTestCases、nPeople、nIndex和nTotalTime都是常数级的空间。
2.空间复杂度:因此,总的空间复杂度为O(1),因为无论测试用例数量和人数多少,空间需求都是固定的(数组大小固定为1001,且所有变量都是常数级别)。
综上所述,空间复杂度为O(1)。
三、POJ1017 Packets
3.1问题描述
问题截图

图3.1 问题截图
输入
输入文件由指定订单的几行组成。每行指定一个订单。顺序由六个整数描述,用一个空格分隔,依次表示从最小尺寸 1*1 到最大尺寸 6*6 的单个大小的数据包数。输入文件的末尾由包含六个零的行表示。
输出
输出文件包含输入文件中每行的一行。此行包含可以将输入文件相应行的订单打包到的最小包裹数量。输出文件中没有与输入文件的最后一行“null”对应的行。
3.2解题思路
题解
针对这道问题,我们可以优化逻辑来确保在装箱过程中最大化地利用空间,并且按照箱子规格从大到小的顺序进行贪心装箱。首先将所有箱子按照规格从大到小进行排序,例如先处理6x6、5x5、4x4的箱子,然后是3x3、2x2和1x1的箱子。对于6x6的箱子,因为只能装一个且全占满,所以直接用一个新箱子装一个6x6的箱子。对于5x5的箱子,同样用一个新箱子装一个5x5的箱子,然后检查是否可以装入1x1的箱子。对于4x4的箱子,同样先用新箱子装一个4x4的箱子,然后尽可能多地装入1x1或2x2的箱子。对于每个3x3的箱子,考虑放入已有箱子中的剩余空间或者使用新箱子。如果使用新箱子,则根据剩余空间可以装入的2x2箱子数量(0, 1, 3, 5)来确定是装4个、3个、2个还是1个3x3的箱子。如果将3x3的箱子放入已有箱子,则检查剩余空间并尽可能多地装入1x1或2x2的箱子。优先将2x2和1x1的箱子放入前面步骤中留下的剩余空间中。如果剩余空间不足以装下一个完整的2x2或1x1箱子,则使用新箱子来装它们。在装入箱子时,要始终保持记录哪些箱子有剩余空间以及剩余空间的大小。当有多个箱子可选时(例如,一个已有箱子剩余空间可以装一个2x2或两个1x1),优先选择能装入更大规格箱子的箱子,以最大化空间利用。计算出所有箱子被装入后所需的总箱子数。最终输出总箱子数作为结果。
通过上述步骤,我们可以确保在装箱过程中最大化地利用了空间,并且按照箱子规格从大到小的顺序进行了贪心装箱,这样可以有效地减少所需的总箱子数。
算法设计路线
这个算法的目的是计算所需的最少箱子数量,以便能够装下所有规格的箱子。每种规格的箱子都有固定的体积和占用空间。算法通过贪心策略逐步计算出所需的最少箱子数量。具体步骤如下:读取各规格箱子的数量:1x1, 2x2, 3x3, 4x4, 5x5, 6x6。如果所有箱子的数量都是0,则结束输入循环。将所有6x6, 5x5, 4x4箱子单独装箱。计算装3x3箱子的最少箱子数量,每4个3x3箱子需要一个箱子,若有剩余则需额外的箱子。每个4x4箱子可以额外装5个2x2箱子。计算未装满的3x3箱子对2x2箱子的影响(每个3x3箱子可影响剩余的2x2箱子空间)。计算是否需要额外的箱子来装2x2箱子,若需要则增加箱子的数量。计算总箱子数剩余的1x1箱子空间,若需要则增加箱子的数量。输出当前测试用例的最少箱子数量。
3.3 C++源代码
#include <iostream>
using namespace std;
int main() {
int nBoxes1x1, nBoxes2x2, nBoxes3x3, nBoxes4x4, nBoxes5x5, nBoxes6x6; // 各种规格箱子的数量
int nRemainingSpace1x1, nRemainingSpace2x2; // 分别为规格1和规格2的箱子剩余的空间
int nTotalBoxes; // 所需的箱子总数量
while (true) {
// 读取输入
cin >> nBoxes1x1 >> nBoxes2x2 >> nBoxes3x3 >> nBoxes4x4 >> nBoxes5x5 >> nBoxes6x6;
// 当所有箱子的数量都为0时,退出循环
if (nBoxes1x1 + nBoxes2x2 + nBoxes3x3 + nBoxes4x4 + nBoxes5x5 + nBoxes6x6 == 0) {
break;
}
// 计算所需的箱子总数量
nTotalBoxes = nBoxes6x6 + nBoxes4x4 + nBoxes5x5 + (nBoxes3x3 + 3) / 4;
// 计算规格为2的箱子剩余空间
nRemainingSpace2x2 = nBoxes4x4 * 5; // 规格4的箱子每个还能装5个规格2的箱子
// 判断规格为3的箱子数量
if (nBoxes3x3 % 4 == 3) {
nRemainingSpace2x2 += 1;
}
else if (nBoxes3x3 % 4 == 2) {
nRemainingSpace2x2 += 3;
}
else if (nBoxes3x3 % 4 == 1) {
nRemainingSpace2x2 += 5;
}
// 如果规格1和规格2的箱子仍没有装完
if (nRemainingSpace2x2 < nBoxes2x2) {
nTotalBoxes += ((nBoxes2x2 - nRemainingSpace2x2) + 8) / 9;
}
// 计算规格1的箱子剩余空间
nRemainingSpace1x1 = 36 * nTotalBoxes - 36 * nBoxes6x6 - 25 * nBoxes5x5 - 16 * nBoxes4x4 - 9 * nBoxes3x3 - 4 * nBoxes2x2;
if (nRemainingSpace1x1 < nBoxes1x1) {
nTotalBoxes += ((nBoxes1x1 - nRemainingSpace1x1) + 35) / 36;
}
// 输出所需的箱子总数量
cout << nTotalBoxes << endl;
}
return 0;
}
正确解题截图
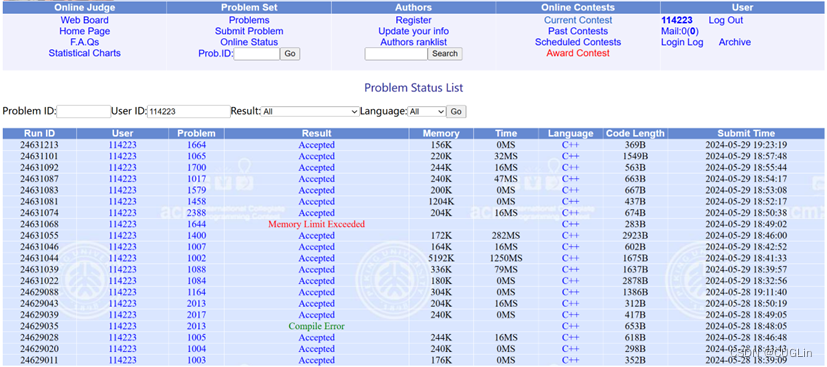
图3.2 正确解题截图
3.4复杂度分析
时间复杂度
1.读取输入和初始化:O(1)。
2.初步计算箱子数量:O(1)。
3.计算规格2的剩余空间:O(1)。
4.计算需要额外的2x2箱子数量:O(1)。
5.计算规格1的剩余空间:O(1)。
6.输出结果: O(1)。
综上所述,每个测试用例的时间复杂度是O(1)。对于 m 个测试用例,总的时间复杂度是O(m)。
空间复杂度
算法只使用了几个常数级别的变量来存储输入和中间结果,如 nBoxes1x1, nBoxes2x2, nBoxes3x3, nRemainingSpace1x1, nRemainingSpace2x2 等。算法不依赖于输入大小来分配额外的空间。综上所述,空间复杂度是 O(1)。
四、POJ1065 Wooden Sticks
4.1问题描述
问题描述

图4.1 问题截图
输入
输入由 T 个测试用例组成。测试用例数 (T) 在输入文件的第一行中给出。每个测试用例由两行组成:第一行有一个整数 n , 1 <= n <= 5000 ,表示测试用例中木棍的数量,第二行包含 2n 个正整数 l1 , w1 , l2 , w2 ,..., ln , wn ,每个数量级最多 10000,其中 li 和 wi 是第 i 根木棍的长度和重量, 分别。2n 个整数由一个或多个空格分隔。
输出
输出应包含最短设置时间(以分钟为单位),每行一个。
4.2解题思路
题解
针对这道问题,一个简单的思路就是根据长度排序,然后找出每一个节点前面的重量小于它的节点,最为一个子序列,在找子序列时,为了不影响到后面节点的子序列,需要找出自己能够接受的重量最大的工件放在前面,同时标记已经选过的节点,这里用到了一点点的贪心算法,最后用DP数组记录每一个工件在子序列中的顺序。最后只需要统计出每一个子序列中顺序为1的个数,就可以找到子序列的个数,子序列的个数就是本题目的答案。
算法设计路线
这里首先读取每个测试用例中的矩形数量。初始化动态规划数组和标志数组。读取每个矩形的长和宽。对矩形数组按照长和宽进行排序。使用双重循环计算每个矩形的最长递增子序列长度。内部循环用于查找前一个矩形能否接在当前矩形后面,形成递增子序列,并更新最长递增子序列的长度。统计最长递增子序列的数量。
4.3 C++源代码
#include <iostream>
#include <algorithm>
using namespace std;
// 定义节点结构体,表示每个矩形的长和宽
struct SNode
{
int nLength; // 矩形的长度
int nWidth; // 矩形的宽度
SNode(int nL = 0, int nW = 0) : nLength(nL), nWidth(nW) {}
};
int anDp[5007]; // 动态规划数组,用于存储最长递增子序列的长度
int nNodesCount; // 矩形的数量
bool abFlag[5007]; // 标志数组,标记哪些矩形已被处理
SNode aNodes[5007]; // 矩形数组
// 比较函数,用于排序节点
bool CompareNodes(const SNode& rNodeA, const SNode& rNodeB)
{
if (rNodeA.nLength != rNodeB.nLength)
{
return rNodeA.nLength < rNodeB.nLength;
}
else
{
return rNodeA.nWidth < rNodeB.nWidth;
}
}
// 初始化数组
void Initialize()
{
for (int nIndex = 0; nIndex <= nNodesCount; nIndex++)
{
anDp[nIndex] = 1; // 初始化每个位置的最长递增子序列长度为1
abFlag[nIndex] = true; // 初始化每个位置的标志为true
}
}
// 输入函数
void Input()
{
for (int nIndex = 1; nIndex <= nNodesCount; nIndex++)
{
scanf("%d%d", &aNodes[nIndex].nLength, &aNodes[nIndex].nWidth); // 输入每个矩形的长和宽
}
sort(aNodes + 1, aNodes + nNodesCount + 1, CompareNodes); // 按照长和宽进行排序
}
// 动态规划函数
void PerformDp()
{
int nMaxIdx = -1; // 存储当前最长递增子序列的前一个位置
int nMaxVal = -1; // 存储当前最长递增子序列的前一个位置的宽度值
for (int nCurrentIdx = 1; nCurrentIdx <= nNodesCount; nCurrentIdx++)
{
anDp[nCurrentIdx] = 1; // 初始化当前矩形的最长递增子序列长度为1
nMaxIdx = -1; // 初始化最大索引为-1
nMaxVal = -1; // 初始化最大值为-1
for (int nPrevIdx = nCurrentIdx - 1; nPrevIdx >= 1; nPrevIdx--)
{
// 判断当前矩形能否接在前一个矩形后面形成递增子序列
if (abFlag[nPrevIdx] && aNodes[nCurrentIdx].nWidth >= aNodes[nPrevIdx].nWidth)
{
// 如果当前前一个矩形的宽度大于最大值或在相同宽度下前一个索引较大,则更新最大值和最大索引
if (nMaxVal < aNodes[nPrevIdx].nWidth || (nMaxVal == aNodes[nPrevIdx].nWidth && nMaxIdx < nPrevIdx))
{
nMaxVal = aNodes[nPrevIdx].nWidth;
nMaxIdx = nPrevIdx;
}
}
}
// 如果找到有效的前一个矩形,则更新当前矩形的最长递增子序列长度,并标记前一个矩形为已处理
if (nMaxIdx >= 1)
{
anDp[nCurrentIdx] = anDp[nMaxIdx] + 1;
abFlag[nMaxIdx] = false;
}
}
}
// 找到结果,即找到最长递增子序列的长度
int FindResult()
{
int nResult = 0; // 初始化结果为0
for (int nIndex = 1; nIndex <= nNodesCount; nIndex++)
{
if (anDp[nIndex] == 1) // 统计长度为1的子序列个数
{
nResult++;
}
}
return nResult; // 返回结果
}
int main()
{
int nTestCases; // 测试用例数量
scanf("%d", &nTestCases);
while (nTestCases--)
{
scanf("%d", &nNodesCount); // 输入每个测试用例中的矩形数量
Initialize(); // 初始化数组
Input(); // 输入矩形数据并排序
PerformDp(); // 执行动态规划计算
printf("%d\n", FindResult()); // 输出结果
}
return 0;
}
正确结题截图
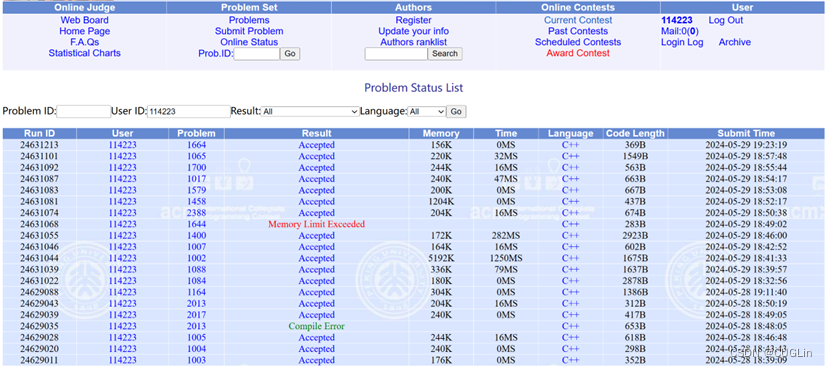
图4.2 正确解题截图
4.4复杂度分析
时间复杂度
1.输入和初始化: O(n)
2.排序: O(n log n)
3.动态规划计算: O(n^2)
4.统计结果: O(n)
综上所述,对于每个测试用例,总的时间复杂度为 O(n^2)。
空间复杂度
算法使用了几个大小为 n 的数组:
1.anDp 数组:存储每个位置的最长递增子序列长度。
2.abFlag 数组:标记哪些矩形已被处理。
3.aNodes 数组:存储矩形的长和宽。
综上所述,总的空间复杂度为 O(n)。
五、实习小结
经过本次贪心算法的上机实习,我深刻体验了贪心算法的核心思想和实际应用。在实习过程中,我不仅巩固了理论知识,还通过编程实践加深了对贪心算法的理解。
我系统回顾了贪心算法的基本原理,即每一步都选择当前状态下的最优解,期望通过这些局部最优解最终导出全局最优解。通过深入学习,我了解到贪心算法的关键在于“贪心”的选择标准,这需要对问题的本质有深刻的理解。
在编程实践中,我解决了多个经典的贪心算法问题,如活动选择问题、背包问题的贪心近似解等。这些实践让我更加熟悉了贪心算法的实现过程,并锻炼了我的编程能力。在解决这些问题的过程中,我体会到了贪心算法的优势和局限性,并学会了如何根据问题的特点选择合适的贪心策略。
同时,我也意识到了贪心算法在实际应用中的挑战。有些问题虽然可以使用贪心算法解决,但得到的解可能不是全局最优解。因此,在选择使用贪心算法时,我们需要对问题的性质进行仔细分析,确保贪心策略的有效性。
此外,在实习过程中,我还注重了代码的优化和性能分析。我尝试使用不同的数据结构来存储中间结果,以减少时间复杂度和空间复杂度。同时,我也对算法的执行效率进行了测试和分析,以找出可能的性能瓶颈。
总的来说,本次贪心算法的上机实习让我收获颇丰。我不仅掌握了贪心算法的基本原理和实现方法,还学会了如何将其应用于实际问题中。同时,我也认识到了贪心算法的局限性和挑战,这将对我未来的学习和工作产生积极的影响。在未来,我将继续深入学习算法知识,提高自己的编程能力和问题解决能力。